堆 这种数据结构是比较难搞的一种,但是它在实际工程中的实用性又比较高,能够有效的解决实际中遇见的问题。
那么在 go语言中是如何要实现一个heap的呢,其实在官方标准库 container/heap 已经给你实现了,你只需要根据自己实际情况进行接口实现即可。
1. 堆的知识梳理
堆的概念:
堆这种数据结构的应用场景非常多,最经典的莫过于堆排序了。堆排序是一种原地的、时间复杂度为 O(nlogn)
- 堆是一个完全二叉树
- 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
大顶堆: 堆中每一个节点的值都必须大于等于其子树中每个节点的值。
小顶堆:堆中每一个节点的值都必须小于等于其子树中每个节点的值。
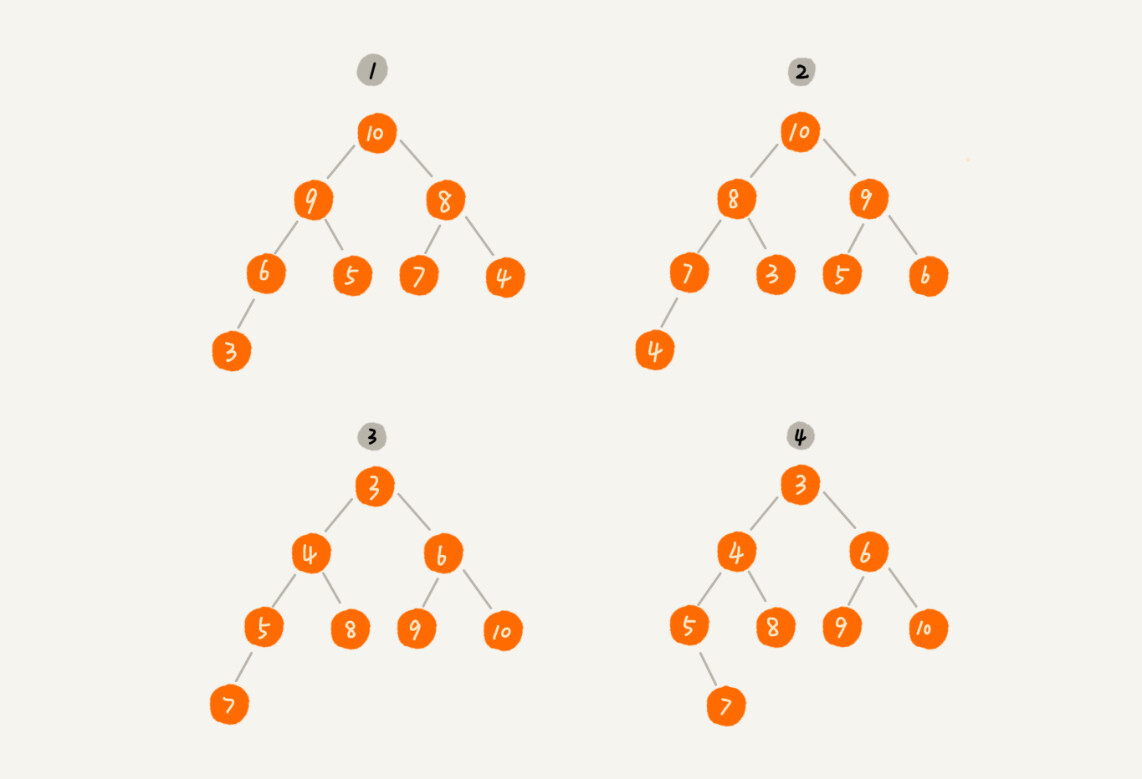
1,2为 大顶堆
3 小顶堆
4 不是堆
堆的操作(堆化)
堆化非常简单,就是顺着节点所在的路径,向上或者向下,对比,然后交换。
往堆中插入元素(从下往上)
给出一个大顶堆,然后从末尾插入一个元素两张图可以展示整个过程演示:
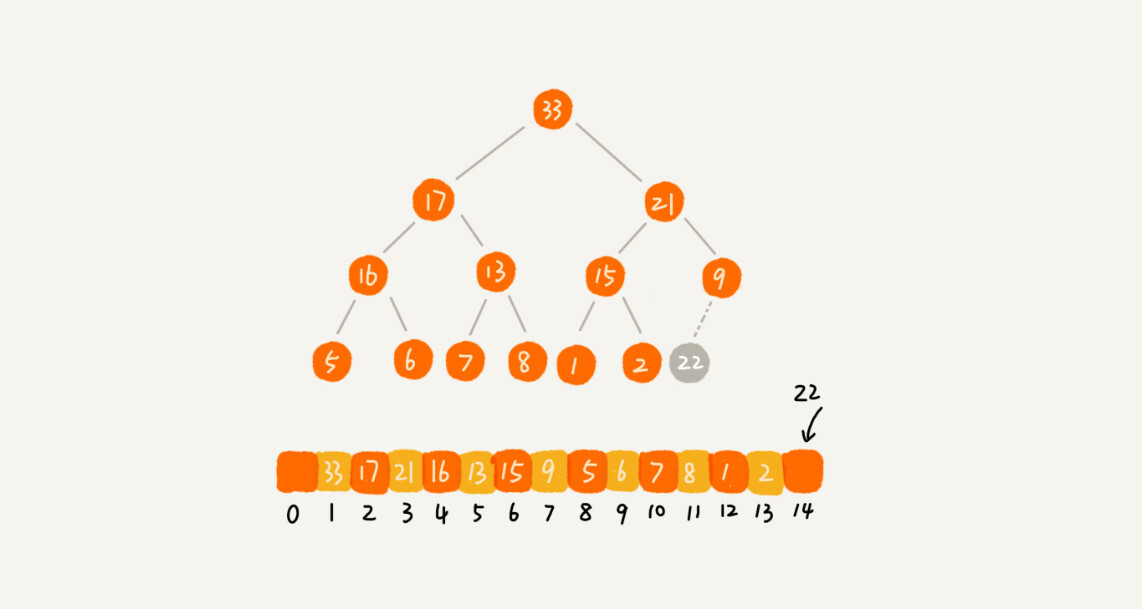
插入过程示意图:
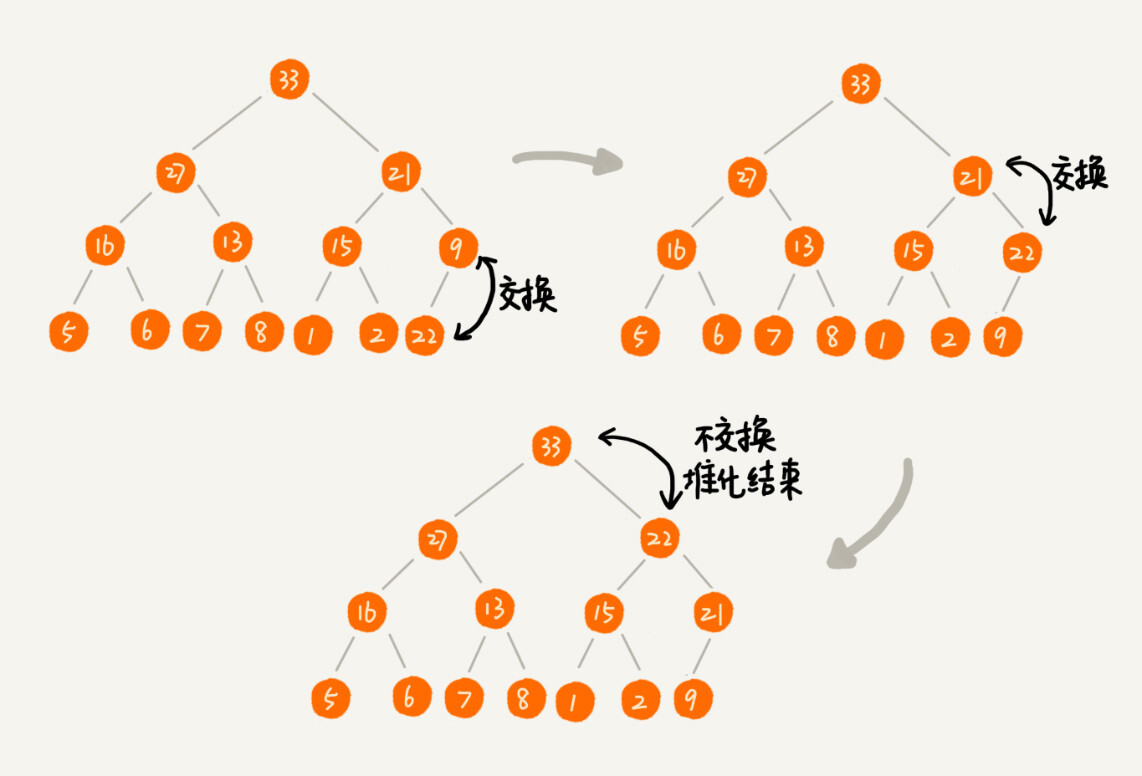
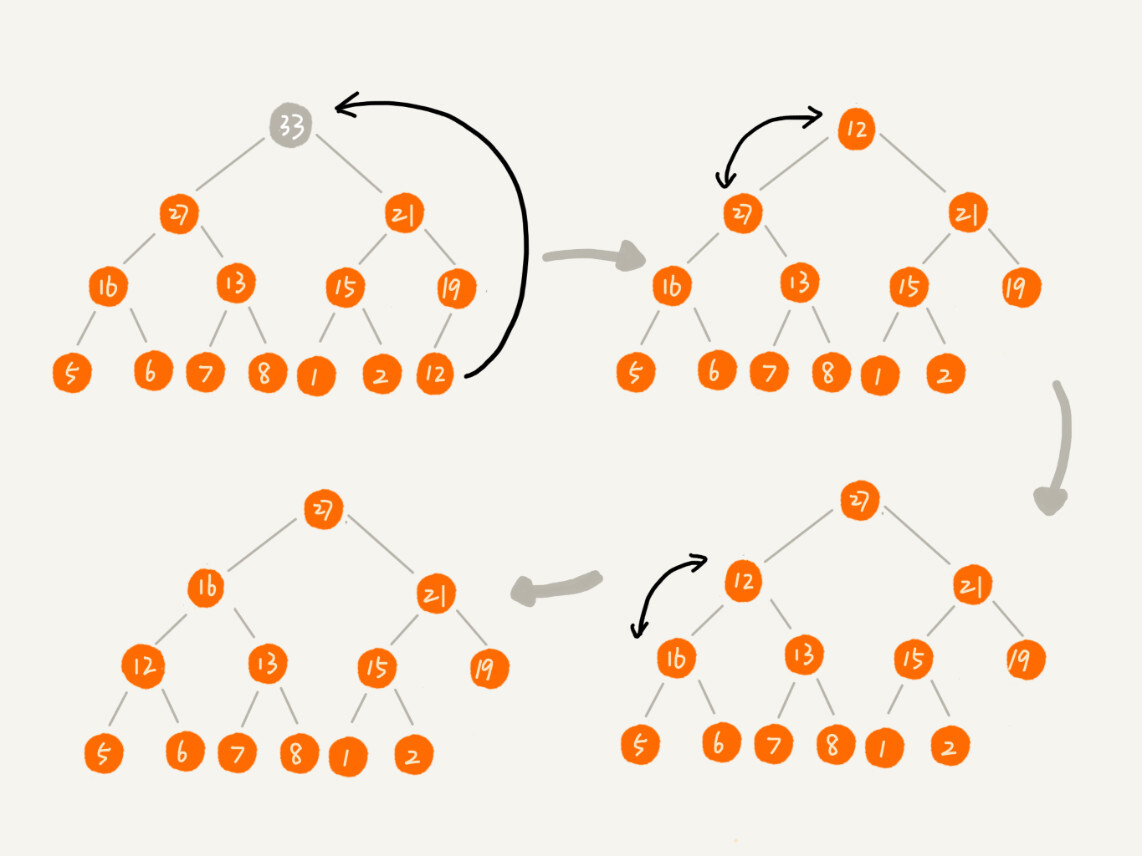
删除堆顶元素(从上往下)
由于堆的特性,所有堆顶元素不是最大值就是最小值。删除堆顶元素后,我们还是需要堆化的过程。
删除比较特殊,为了避免出现 “数组空洞问题” 如下图:
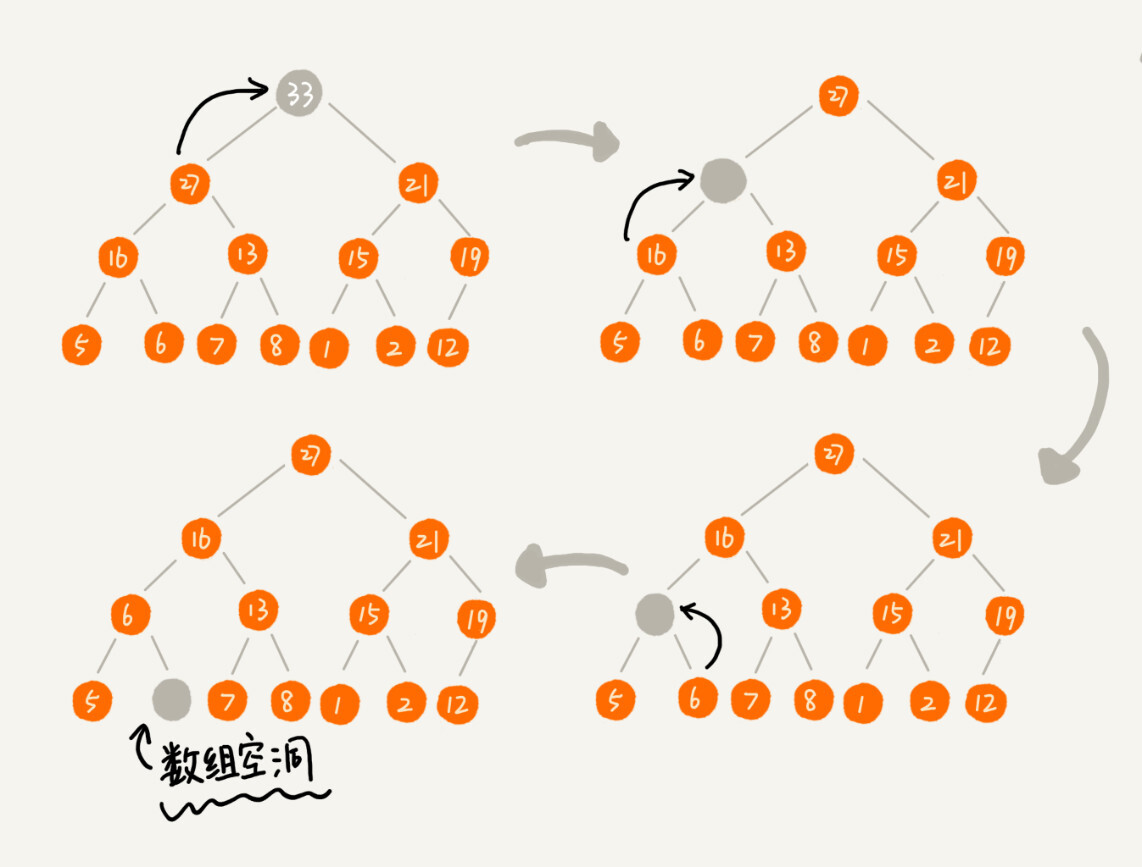
我们可以直接将堆顶元素与最后一个元素交换,直接删除掉堆顶元素,再进行堆化的过程即可。
实现堆排序(建堆和排序)
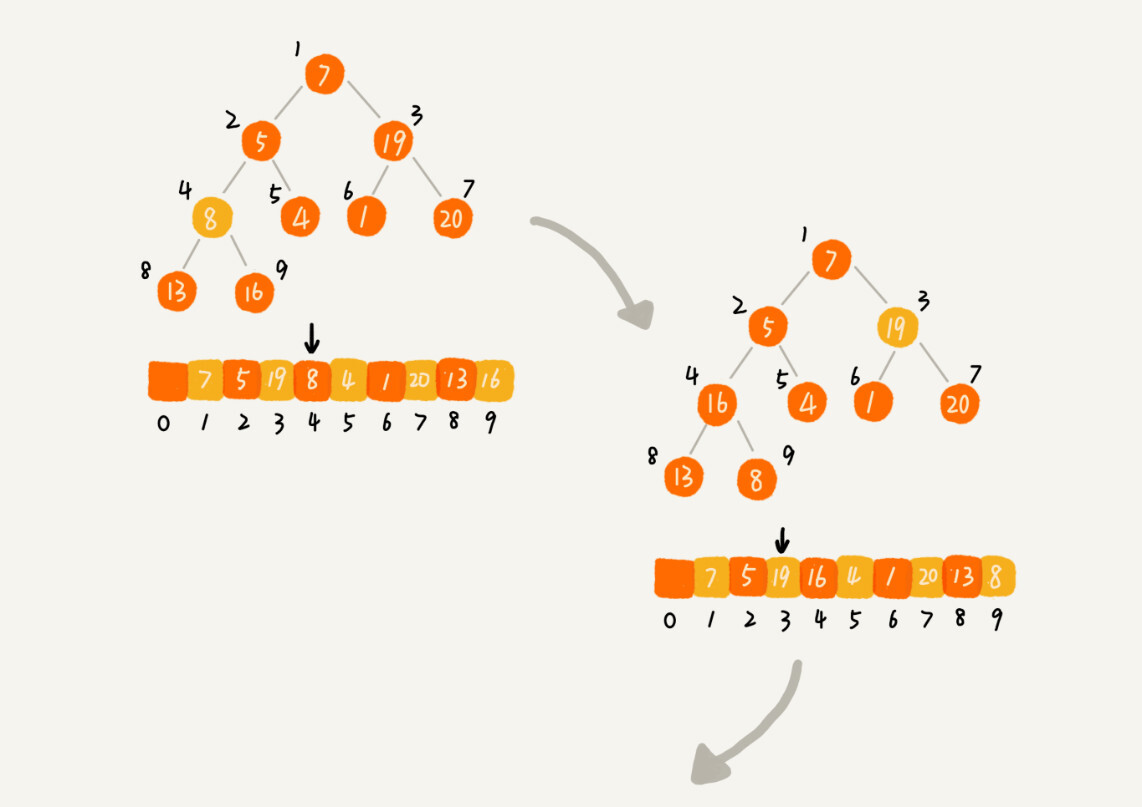
建堆
建堆的时间复杂度就是 O(n)
一种建堆思路的处理过程是从前往后处理数组数据,并且每个数据插入堆中时,都是从下往上堆化。
而这里推荐的是第二种实现思路,是从后往前处理数组,并且每个数据都是从上往下堆化。如图所示:
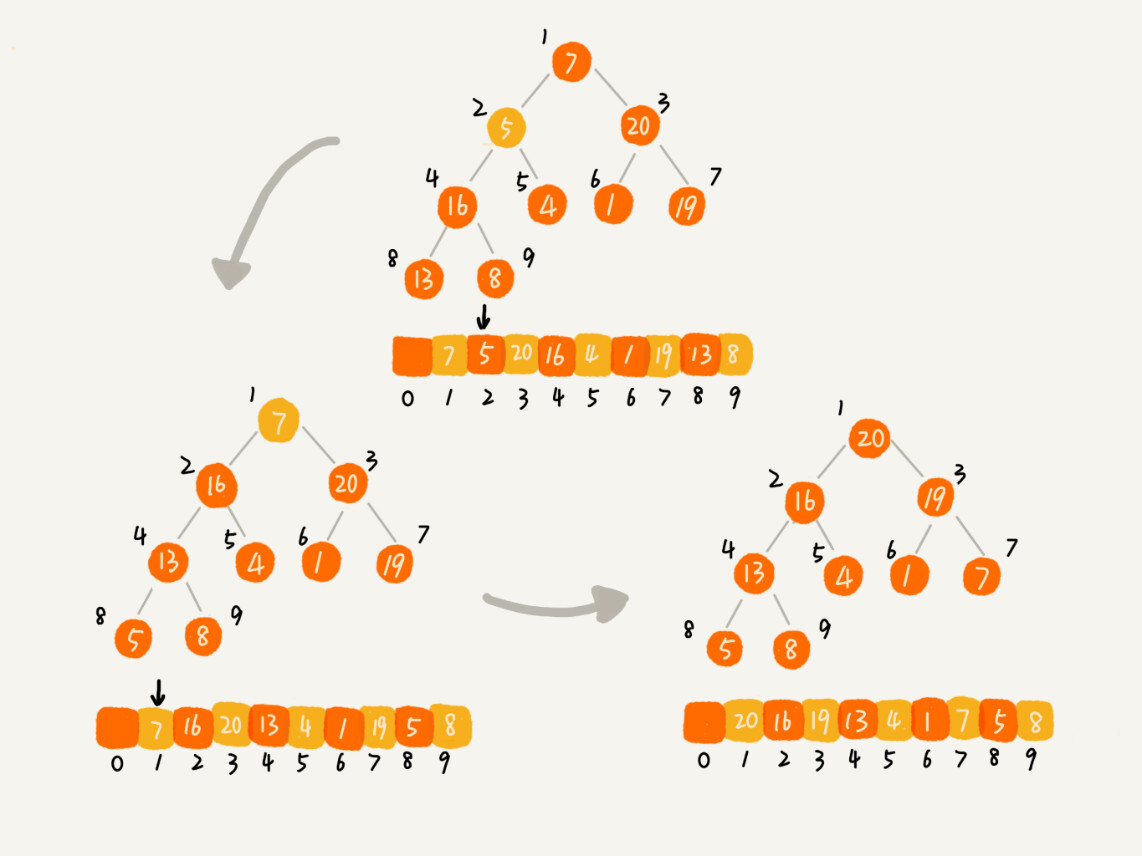
排序
上面建堆过程中我们可以得到一个大顶堆,堆顶为最大元素值,然后我们仿照着“删除堆顶元素”的方式进行排序即可。
不断的把堆顶元素和最后一个元素交换位置再将前面n-1和元素堆化,如下图:
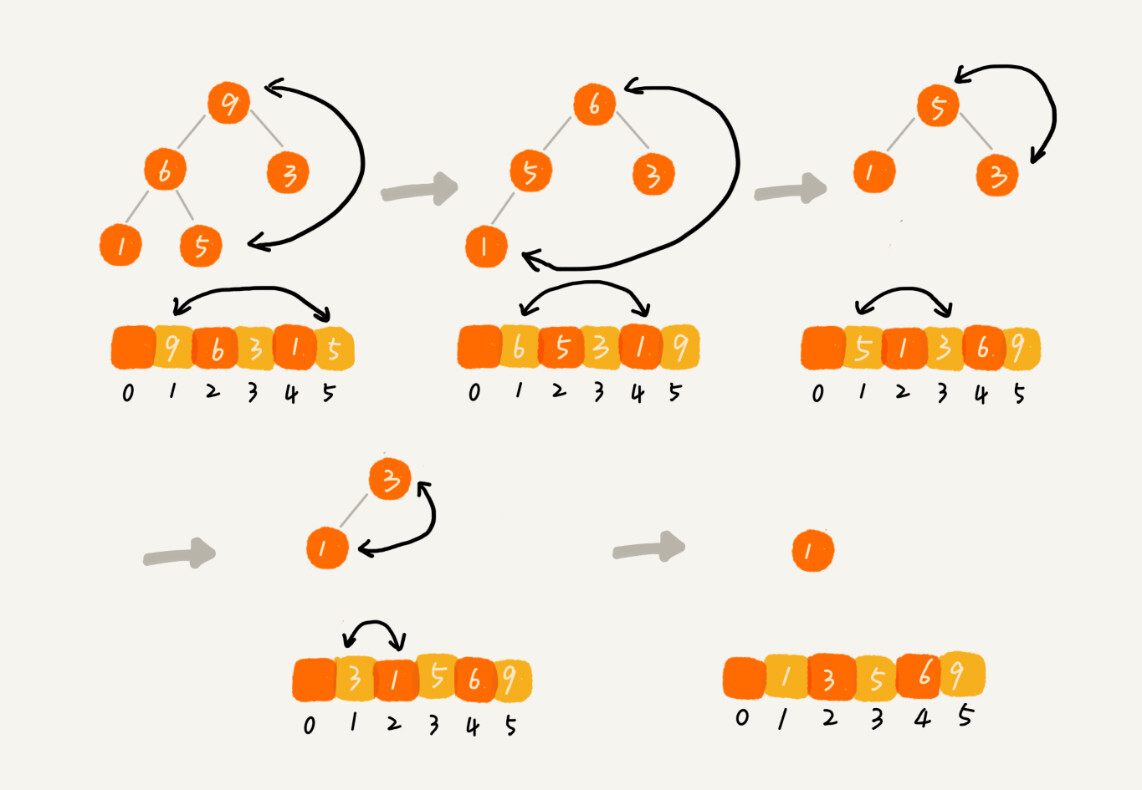
整个堆排序的过程,都只需要极个别临时存储空间,所以堆排序是原地排序算法。
堆排序包括建堆和排序两个操作,建堆过程的时间复杂度是 O(n),而排序时间复杂度为 O(nlogn)。
所以,堆排序整体的时间复杂度是 O(nlogn)。
堆排序不是稳定的排序算法,因为在排序的过程,存在将堆的最后一个节点跟堆顶节点互换的操作,所以就有可能改变值相同数据的原始相对顺序。
参考文章
2. heap 堆的实现 go语言版
在go的标准库 container/heap 以后给出了现存的堆结构我们只需要进行接口实现和调用接口即可,具体如下:
import (
"container/heap"
"fmt"
)
type IntHeap []int
func main() {
h := &IntHeap{2, 1, 5, 6, 4, 3, 7, 9, 8, 0} // 创建slice
heap.Init(h) // 将数组切片进行堆化
fmt.Println(*h) // [0 1 3 6 2 5 7 9 8 4] 由Less方法可控制小顶堆
fmt.Println(heap.Pop(h)) // 调用pop 0 返回移除的顶部最小元素
heap.Push(h, 6) // 调用push [1 2 3 6 4 5 7 9 8] 添加一个元素进入堆中进行堆化
fmt.Println("new: ", *h) // [1 2 3 6 4 5 7 9 8 6]
for len(*h) > 0 { // 持续推出顶部最小元素
fmt.Printf("%d \n ", heap.Pop(h))
}
}
func (h IntHeap) Len() int { return len(h) }
func (h IntHeap) Less(i, j int) bool { return h[i] < h[j] } // 这里决定 大小顶堆 现在是小顶堆
func (h IntHeap) Swap(i, j int) {
h[i], h[j] = h[j], h[i]
}
func (h *IntHeap) Pop() interface{} {
old := *h
n := len(old)
fmt.Println("old: ", old) // [1 2 3 6 4 5 7 9 8 0] 将顶小堆元素与最后一个元素交换位置,在进行堆排序的结果
x := old[n-1]
*h = old[0 : n-1]
fmt.Println(*h) // [1 2 3 6 4 5 7 9 8]
return x
}
func (h *IntHeap) Push(x interface{}) { // 绑定push方法,插入新元素
*h = append(*h, x.(int))
}理解以上代码需要结合上面的堆知识梳理中的“堆化”和“删除元素” + “插入元素”。
再来看看heap包的源码:
- 首先要调用heap.Init()方式传入的参数必须是已经实现Interface对应接口的。
// The Interface type describes the requirements
// for a type using the routines in this package.
// Any type that implements it may be used as a
// min-heap with the following invariants (established after
// Init has been called or if the data is empty or sorted):
//
// !h.Less(j, i) for 0 <= i < h.Len() and 2*i+1 <= j <= 2*i+2 and j < h.Len()
//
// Note that Push and Pop in this interface are for package heap's
// implementation to call. To add and remove things from the heap,
// use heap.Push and heap.Pop.
type Interface interface { // 该接口组合了另外的sort.Interface接口,所以也要实现里面的方法
sort.Interface
Push(x interface{}) // add x as element Len()
Pop() interface{} // remove and return element Len() - 1.
}
// Init establishes the heap invariants required by the other routines in this package.
// Init is idempotent with respect to the heap invariants
// and may be called whenever the heap invariants may have been invalidated.
// The complexity is O(n) where n = h.Len().
func Init(h Interface) {
// heapify
n := h.Len()
for i := n/2 - 1; i >= 0; i-- {
down(h, i, n)
}
}其中 sort.Interface接口:
package sort
// A type, typically a collection, that satisfies sort.Interface can be
// sorted by the routines in this package. The methods require that the
// elements of the collection be enumerated by an integer index.
type Interface interface {
// Len is the number of elements in the collection.
Len() int
// Less reports whether the element with
// index i should sort before the element with index j.
Less(i, j int) bool
// Swap swaps the elements with indexes i and j.
Swap(i, j int)
}再回来看看heap包中的其他方法:
// Push pushes the element x onto the heap.
// The complexity is O(log n) where n = h.Len().
func Push(h Interface, x interface{}) {
h.Push(x)
up(h, h.Len()-1)
}
// Pop removes and returns the minimum element (according to Less) from the heap.
// The complexity is O(log n) where n = h.Len().
// Pop is equivalent to Remove(h, 0).
func Pop(h Interface) interface{} {
n := h.Len() - 1
h.Swap(0, n)
down(h, 0, n)
return h.Pop()
}
// Remove removes and returns the element at index i from the heap.
// The complexity is O(log n) where n = h.Len().
func Remove(h Interface, i int) interface{} {
n := h.Len() - 1
if n != i {
h.Swap(i, n)
if !down(h, i, n) {
up(h, i)
}
}
return h.Pop()
}
// Fix re-establishes the heap ordering after the element at index i has changed its value.
// Changing the value of the element at index i and then calling Fix is equivalent to,
// but less expensive than, calling Remove(h, i) followed by a Push of the new value.
// The complexity is O(log n) where n = h.Len().
func Fix(h Interface, i int) {
if !down(h, i, h.Len()) {
up(h, i)
}
}
func up(h Interface, j int) {
for {
i := (j - 1) / 2 // parent
if i == j || !h.Less(j, i) {
break
}
h.Swap(i, j)
j = i
}
}
func down(h Interface, i0, n int) bool {
i := i0
for {
j1 := 2*i + 1
if j1 >= n || j1 < 0 { // j1 < 0 after int overflow
break
}
j := j1 // left child
if j2 := j1 + 1; j2 < n && h.Less(j2, j1) {
j = j2 // = 2*i + 2 // right child
}
if !h.Less(j, i) {
break
}
h.Swap(i, j)
i = j
}
return i > i0
}总结方法如下:
h := &IntHeap{3, 8, 6} // 创建IntHeap类型的原始数据
func Init(h Interface) // 对heap进行初始化,生成小根堆(或大根堆)
func Push(h Interface, x interface{}) // 往堆里面插入内容
func Pop(h Interface) interface{} // 从堆顶pop出内容
func Remove(h Interface, i int) interface{} // 从指定位置删除数据,并返回删除的数据
func Fix(h Interface, i int) // 从i位置数据发生改变后,对堆再平衡,优先级队列使用到了该方法在堆的应用中下面会用 heap 实现一个优先队列。
参考文档
官方文档
3. 堆的实际应用和解决方案
一. 优先级队列
优先级最高的,最先出队。
优先级队列,顾名思义,它首先应该是一个队列。
队列最大的特性就是先进先出。
不过,在优先级队列中,数据的出队顺序不是先进先出,而是按照优先级来,优先级最高的,最先出队
用堆来实现优先级队列是最直接、最高效的。
这是因为,堆和优先级队列非常相似。
一个堆就可以看作一个优先级队列。 很多时候,它们只是概念上的区分而已。
往优先级队列中插入一个元素,就相当于往堆中插入一个元素;从优先级队列中取出优先级最高的元素,就相当于取出堆顶元素。
下面是两个具体的列子,告诉我们优先队列的具体应用场景。
1. 合并有序小文件
场景一 需求说明:
有100个文件,每个文件大小都是100M,然后每个文件里面存储的都是字符串,现在需要将这100个文件合并成一个有序的大文件。
解决方案一 数组法:
取出每个文件的第一个字符串,总共就是100个字符串放入到一个数组中。
然后再这个数组中比较大小,将最小的那个放入的最终的大文件中,并从之前的数组中删掉。
假设这个字符串是 12.txt 这个文件中的,那我们就再从这个文件中取出一个字符串来,然后放入到之前的数组中,重新比较大小,并选择最小的那个再次放入到最终的大文件中。
以此类推,直到所有文件中的数据都放入到了大文件中即可。
这里我们用数组这种数据结构,来存储从小文件中取出来的字符串。每次从数组中取最小字符串,都需要循环遍历整个数组,显然,这不是很高效。下面我们用优先队列。
解决方案二 优先队列(推荐):
我们将从小文件中取出来的字符串放入到小顶堆中,那堆顶的元素,也就是优先级队列队首的元素,就是最小的字符串。
我们将这个字符串放入到大文件中,并将其从堆中删除。
然后再从小文件中取出下一个字符串,放入到堆中。循环这个过程,就可以将 100 个小文件中的数据依次放入到大文件中。
这里删除堆元素和往堆中插入数据的时间复杂度都是 O(logn), 而之前的放入数组再每次比较大小为O(n平方)。明显要高效很多了。
2. 高性能定时器
场景二 需求说明
有一个定时器,定时器中维护了很多定时任务,每个任务都设定了一个要触发执行的时间点。定时器每过一个很小的单位时间(比如 1 秒),就扫描一遍任务,看是否有任务到达设定的执行时间。如果到达了,就拿出来执行。请进行优化。
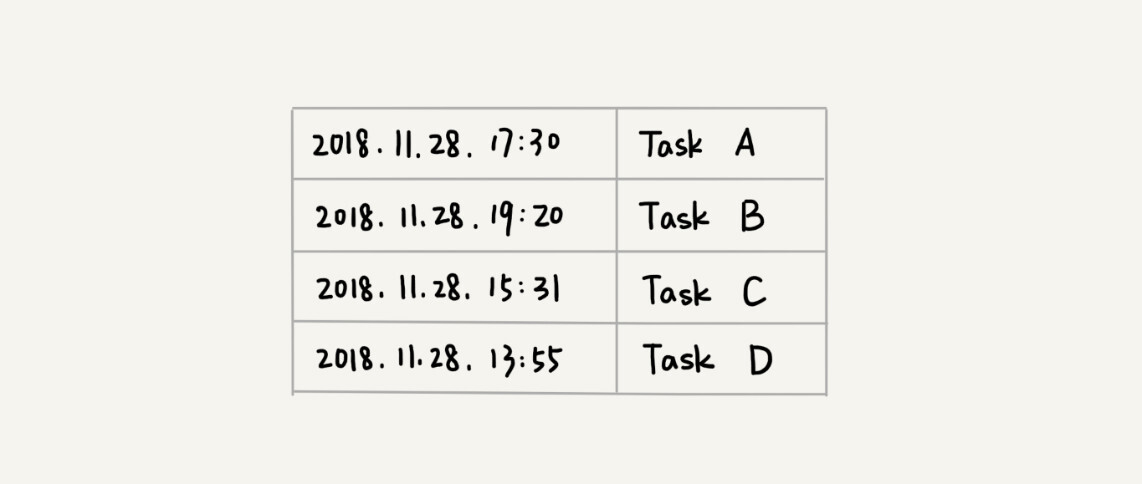
如上所述,这样每隔 1 秒就去扫描的方法比较低效:
- 1. 每个任务的约定执行时间之间可能会隔很久,这样会多出很多无用的扫描。
- 2. 每次都去扫描整个任务列表的话,如果该表比较大,扫描时间间隔又及其短,对性能时间消耗就比较大了。
解决方案 优先队列化
按照任务设定的执行时间,将这些任务存储在优先级队列中,队列首部(也就是小顶堆的堆顶)存储的是最先执行的任务。
这样,定时器就不需要每隔 1 秒就扫描一遍任务列表了。
它先拿队首任务的执行时间点,与当前时间点相减,得到一个时间间隔 T。
这个时间间隔 T 就是,从当前时间开始,需要等待多久,才会有第一个任务需要被执行。
这样,定时器就可以设定在 T 秒之后,再来执行任务。从当前时间点到(T-1)秒这段时间里,定时器都不需要做任何事情。
当 T 秒时间过去之后,定时器取优先级队列中队首的任务执行。然后再计算新的队首任务的执行时间点与当前时间点的差值,把这个值作为定时器执行下一个任务需要等待的时间。
这样,定时器既不用间隔 1 秒就轮询一次,也不用遍历整个任务列表,性能也就提高了。完美!
利用 heap 包实现一个优先队列
import (
"container/heap"
"fmt"
)
type Item struct {
value string // 优先级队列中的数据,可以是任意类型,这里使用string
priority int // 优先级队列中节点的优先级
index int // index是该节点在堆中的位置
}
// 优先级队列需要实现heap的interface
type PriorityQueue []*Item
// 绑定Len方法
func (pq PriorityQueue) Len() int {
return len(pq)
}
// 绑定Less方法,这里用的是小于号,生成的是小根堆
func (pq PriorityQueue) Less(i, j int) bool {
return pq[i].priority < pq[j].priority
}
// 绑定swap方法
func (pq PriorityQueue) Swap(i, j int) {
pq[i], pq[j] = pq[j], pq[i]
pq[i].index, pq[j].index = i, j
}
// 绑定put方法,将index置为-1是为了标识该数据已经出了优先级队列了
func (pq *PriorityQueue) Pop() interface{} {
old := *pq
n := len(old)
item := old[n-1]
*pq = old[0 : n-1]
item.index = -1
return item
}
// 绑定push方法
func (pq *PriorityQueue) Push(x interface{}) {
n := len(*pq)
item := x.(*Item)
item.index = n
*pq = append(*pq, item)
}
// 更新修改了优先级和值的item在优先级队列中的位置
func (pq *PriorityQueue) update(item *Item, value string, priority int) {
item.value = value
item.priority = priority
heap.Fix(pq, item.index)
}
func main() {
// 创建节点并设计他们的优先级
items := map[string]int{"二毛": 5, "张三": 3, "狗蛋": 9}
i := 0
pq := make(PriorityQueue, len(items)) // 创建优先级队列,并初始化
for k, v := range items { // 将节点放到优先级队列中
pq[i] = &Item{
value: k,
priority: v,
index: i}
i++
}
heap.Init(&pq) // 初始化堆
item := &Item{ // 创建一个item
value: "李四",
priority: 1,
}
heap.Push(&pq, item) // 入优先级队列
pq.update(item, item.value, 6) // 更新item的优先级
for len(pq) > 0 {
item := heap.Pop(&pq).(*Item)
fmt.Printf("%.2d:%s index:%.2d\n", item.priority, item.value, item.index)
}
}输出结果为:
输出结果:
03:张三 index:-01
05:二毛 index:-01
06:李四 index:-01
09:狗蛋 index:-01二. 利用堆求 Top K
求这个TOP K 问题可以分为两种情况 - 1. 静态数据 - 2. 动态数据
一类是针对静态数据集合,也就是说数据集合事先确定,不会再变。另一类是针对动态数据集合,也就是说数据集合事先并不确定,有数据动态地加入到集合中。
静态数据:
如何在一个含有 n 个数据的数组中,求出前 k 大的数据呢?
维护一个大小为K的小顶堆(这个堆就保持只有K个元素即可)
从数组中取出一个与堆顶元素比较,如果取出来的元素比堆顶元素大,则删除堆顶元素,再将该数组元素插入到堆中。
相反比堆顶元素小,则不管。直到最后数组中的元素都遍历完了,那么该小顶堆里面的K个元素就是前k大元素了。
请注意,小顶堆中每次移除的就是最小的那个,插入进来再重新堆化。
动态数据:
针对动态数据求得 Top K 就是实时 Top K。
一个数据集合中有两个操作,一个是添加数据,另一个询问当前的前 K 大数据。
我们可以一直都维护一个 K 大小的小顶堆,当有数据被添加到集合中时,我们就拿它与堆顶的元素对比。(这里就不再放入数组中了,而是直接进入堆中进行比较)
如果比堆顶元素大,我们就把堆顶元素删除,并且将这个元素插入到堆中;如果比堆顶元素小,则不做处理。这样,无论任何时候需要查询当前的前 K 大数据,我们都可以立刻返回给他。
三. 利用堆求中位数
如何求动态数据中的中位数
中位数,顾名思义,就是处在中间位置的那个数。如果数据的个数是奇数,把数据从小到大排列,那第 n/2 + 1 个数据就是中位数(注意:假设数据是从 0 开始编号的);如果数据的个数是偶数的话,那处于中间位置的数据有两个,第 n/2 和 n/2 + 1 个数据。
这个时候,我们可以随意取一个作为中位数,比如取两个数中靠前的那个,就是第 n/2 个数据。
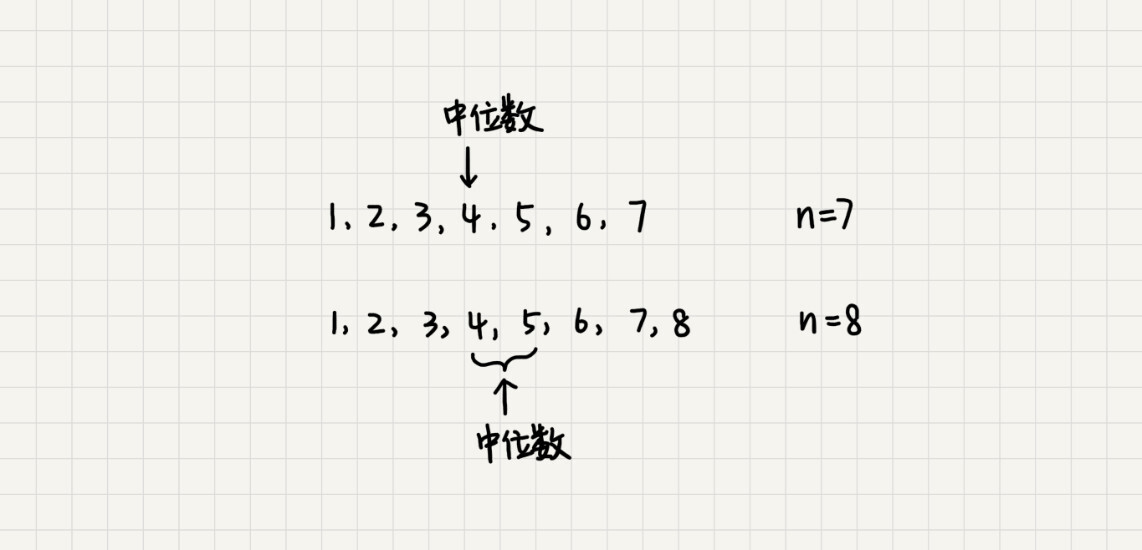
在我们面对动态数据的集合,中位数在不停地变动,如果再用先排序的方法,每次询问中位数的时候,都要先进行排序,那效率就不高了。
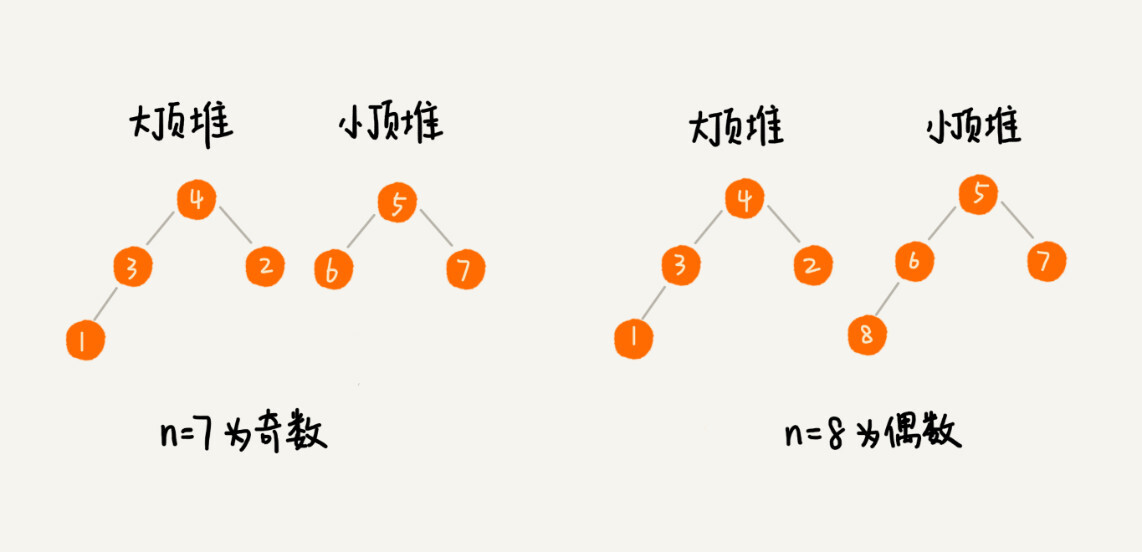
#### 解决方案 维护两个堆 一个小顶堆 一个大顶堆
我们需要维护两个堆,一个大顶堆,一个小顶堆。大顶堆中存储前半部分数据,小顶堆中存储后半部分数据,且小顶堆中的数据都大于大顶堆中的数据。
这里请注意对于奇数和偶数中,大小顶堆的存储分布。
这样存储的话,那么大顶堆堆顶元素就是我们要找的中位数了。如图所示:
如果新加入的数据小于等于大顶堆的堆顶元素,我们就将这个新数据插入到大顶堆;否则,我们就将这个新数据插入到小顶堆。
由于数据是动态变化的,当新添加一个数据的时候,我们如何调整两个堆,让大顶堆中的堆顶元素继续是中位数呢?
当为奇数个数据时,我们可以从一个堆中不停地将堆顶元素移动到另一个堆,通过这样的调整,来让两个堆中的数据满足上面的约定。如下图所示:
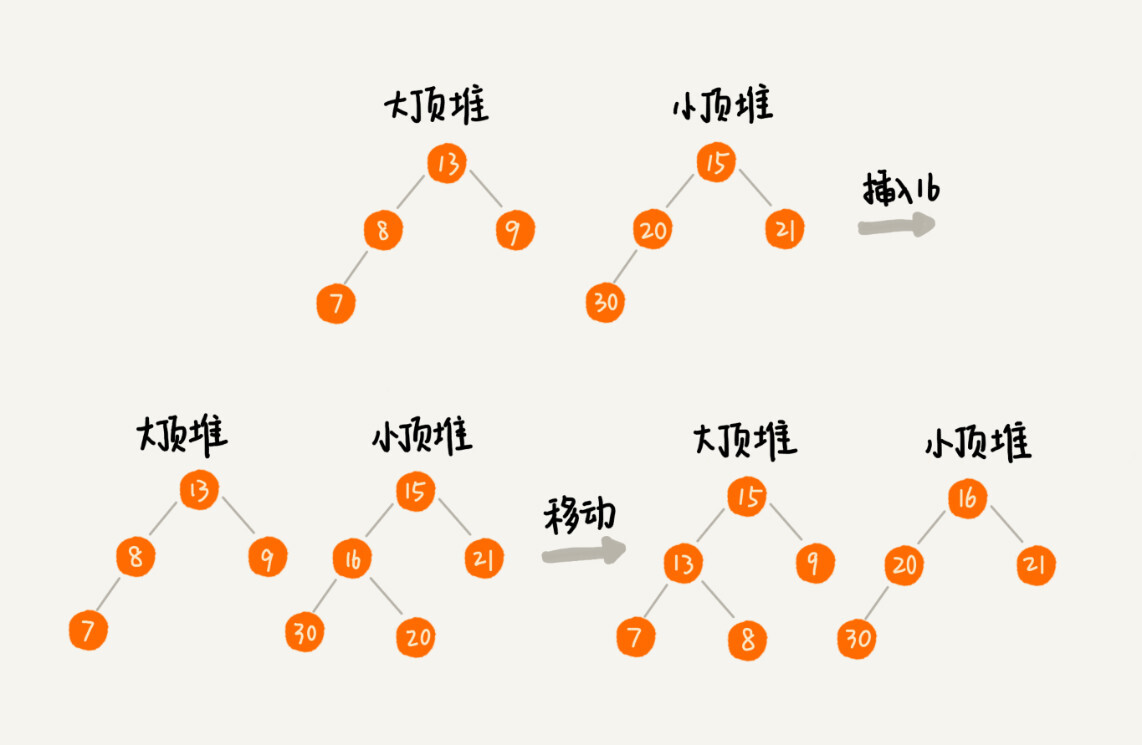
这样我们就可以利用两个堆,一个大顶堆、一个小顶堆,实现在动态数据集合中求中位数的操作。插入数据因为需要涉及堆化,所以时间复杂度变成了 O(logn),但是求中位数我们只需要返回大顶堆的堆顶元素就可以了,所以时间复杂度就是 O(1)。
同样的道理可以看下方求99%的相关问题。
如何快速求接口的99%的响应时间
在开始这个问题的讲解之前,我先解释一下,什么是“99% 响应时间”。
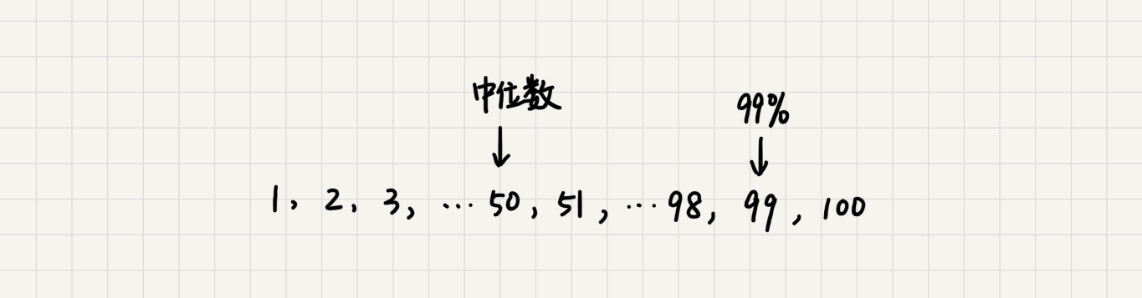
中位数的概念就是将数据从小到大排列,处于中间位置,就叫中位数,这个数据会大于等于前面 50% 的数据。99 百分位数的概念可以类比中位数,如果将一组数据从小到大排列,这个 99 百分位数就是大于前面 99% 数据的那个数据。
弄懂了这个概念,我们再来看 99% 响应时间。如果有 100 个接口访问请求,每个接口请求的响应时间都不同,比如 55 毫秒、100 毫秒、23 毫秒等,我们把这 100 个接口的响应时间按照从小到大排列,排在第 99 的那个数据就是 99% 响应时间,也叫 99 百分位响应时间。
解决方案 维护一个大顶堆,一小顶堆。
我们维护两个堆,一个大顶堆,一个小顶堆。
假设当前总数据的个数是 n,大顶堆中保存 n*99% 个数据,小顶堆中保存 n*1% 个数据。
大顶堆堆顶的数据就是我们要找的 99% 响应时间。
每次插入一个数据的时候,我们要判断这个数据跟大顶堆和小顶堆堆顶数据的大小关系,然后决定插入到哪个堆中。如果这个新插入的数据比大顶堆的堆顶数据小,那就插入大顶堆;如果这个新插入的数据比小顶堆的堆顶数据大,那就插入小顶堆。
但是,为了保持大顶堆中的数据占 99%,小顶堆中的数据占 1%,在每次新插入数据之后,我们都要重新计算,这个时候大顶堆和小顶堆中的数据个数,是否还符合 99:1 这个比例。如果不符合,我们就将一个堆中的数据移动到另一个堆,直到满足这个比例。移动的方法类似前面求中位数的方法,这里我就不啰嗦了。
通过这样的方法,每次插入数据,可能会涉及几个数据的堆化操作,所以时间复杂度是 O(logn)。每次求 99% 响应时间的时候,直接返回大顶堆中的堆顶数据即可,时间复杂度是 O(1)。
小结:
优先级队列是一种特殊的队列,优先级高的数据先出队,而不再像普通的队列那样,先进先出。实际上,堆就可以看作优先级队列,只是称谓不一样罢了。求 Top K 问题又可以分为针对静态数据和针对动态数据,只需要利用一个堆,就可以做到非常高效率的查询 Top K 的数据。求中位数实际上还有很多变形,比如求 99 百分位数据、90 百分位数据等,处理的思路都是一样的,即利用两个堆,一个大顶堆,一个小顶堆,随着数据的动态添加,动态调整两个堆中的数据,最后大顶堆的堆顶元素就是要求的数据。